Research :
ChatGPT to the rescue of texting
Someone may not stop texting you, and they can actually text you even more. But at least you’re not the one putting the effort.
Export iMessage to transcript
I’ve recently stumbled upon imessage-exporter from ReagentX and I thought, why not generate a transcript and feed AI with it?
I’ve made some changes on my fork repo so that you can directly export transcripts.
git clone https://github.com/gbaranski/imessage-exporter.git
cd imessage-exporter/
To export messages run this command in ./imessage-exporter:
cd ./imessage-exporter
# Replace Gregory with your name
cargo run -- --format transcript --export-path /tmp/imessage-transcripts --start-date -m Gregory
Now that you have the exported conversations, open the folder with output, and find a conversation that you’d like to mimic. Copy the file to /tmp/transcript.txt:
cd /tmp/imessage-transcripts
# Replace
cp ./+48500600700.txt ../transcript.txt
The exporter doesn’t make use of Apple Contacts, so you’d typically want to change number to the persons’s name:
sed -i 's/+48500600700/Emma/g' ../transcript.txt
Feeding ChatGPT
Here’s the hardest part, because ChatGPT is putting some limitations on how much text you can put. So you have three options:
- Use only a small chunk of the transcript, for me that provided a slightly better results.
- Use ChatGPT Prompt Splitter, but even if you provide a huge transcript, ChatGPT is going to forget all of this.
- Attach the file directly. Probably the worst results.
Once you’ve decided, here’s the prompt I’ve used to generate responses:
Below I have provided you with a conversation dump between me and my friend Emma.
In next message I'll input you message from Gregory as if they were sent from me, your role will be to mimic responses, as if they were sent by Emma.
Did you understand the task?
PS: Replace Emma & Gregory with the names you’ve previously provided
Results
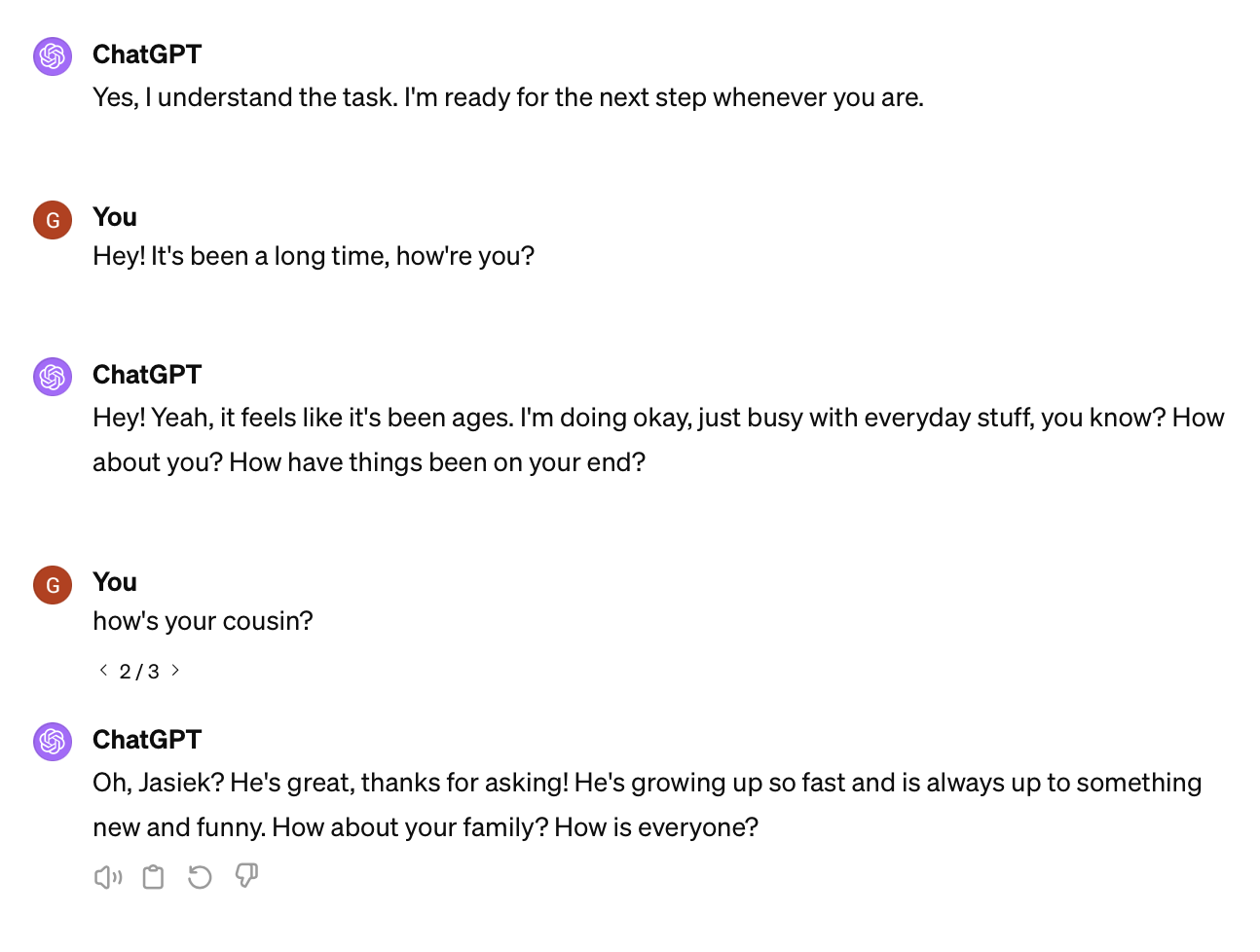 ChatGPT got the cousin’s name right, and the texting style is super generic, that’d trick me, but I don’t know if for long.
ChatGPT got the cousin’s name right, and the texting style is super generic, that’d trick me, but I don’t know if for long.

Not from Italy, but Spain. But also I didn’t mention it anywhere in the texts.

Very quickly I got rate-limited.
Summary
I don’t usually use iMessage, especially for conversations in English, thus I didn’t have a lot of data to play with.
I did however try a few different conversations in Polish, and I did get some results.
I think that’s really going to be a thing once context window of LLMs reach a really high number, so that it’s able to not only process books and papers, but also conversation transcripts.
Claude 3 has a 200K context window, comparing to 32K in GPT-4.
However you’re free to try it out on your own data, the fork isn’t going down anytime soon.
If you got some interesting results, you’re more than invited to reach me out.
Beware of posting controversial stuff:
